

by Raoul Kübler
, 27.07.23
With Jeroen Rombouts
We are living in the most data-rich period of humankind. We create and store more data on a daily basis than our ancestors did in the last 2000 years - combined. This data comes from various digital sources, where consumers leave intentionally (and unintentionally) valuable information for marketers in the form of user-generated content. Raoul Kübler (Associate Professor of Marketing) and Jeroen Rombouts (Professor of Information Systems, Decision Sciences and Statistics and holder of the ESSEC Accenture Strategic Business Analytics Chair) explain what this data can tell us about consumer behavior.
Consumers continuously provide us with insights about what they like about a brand, which products they compare or desire, what aspects of a service they dislike, or what things particularly disappointed them. Each online channel provides us with specific information that we can use to gain information about customer attitudes along the consumer decision journey. Google search volume and number of social media followers may give us an impression about brand knowledge and brand awareness. When it comes to information search behavior and consideration, search-queries from Google or Bing may similarly make us understand what aspects of our brand positioning resonate in a consumer’s mind and which other brands and products in our category are perceived to be equal, superior or inferior to our own product.
Further down the funnel, user-generated content from social media may similarly help us to track customer feelings, preferences, and attitudes and understand metrics like purchase intention, brand meaning, or customer satisfaction. Instagram is famous for being used to praise brands and highlight which products are currently trendy and desirable, and may be a great source to trace brand strength. Twitter is infamous for being the first stop to complain if consumer expectations are not met. This means that both channels may be helpful with tracking customer satisfaction and brand meaning. Similarly, platforms such as Facebook (for a now older target group), TikTok (for a very young target group), Youtube, Reddit, and Snapchat provide managers with plenty of customer insights. Marketers can understand consumers’ brand perceptions (and how they are influenced by their marketing activities) by examining the content they post and how favorable it is compared to other brands. The same data pool allows us to track customers’ mindsets and explain it by marketing activities and also to identify and measure consumer preferences and opinions to identify new segments, product use cases and growth opportunities. To tap into this information pool of user-generated content, managers need to develop a clear understanding of which type of information, for which type of use case they want to extract, to then decide which data sources and tools are required to create insights. In the following we give an overview of potential use cases, corresponding data sources, and the related state-of-the art tools to analyze the different types of data.
Types of Use Cases and Applications in Business
When it comes to uses cases, current business research proposes a framework which combines the source of data with the corporate use case scope. In this framework, data originates from two major sources: data that has been generated inside the company, and data that has to be collected from the outside. Companies can use this data to either explore consumers and markets or to exploit the data to take better informed decisions. The resulting two-by-two framework with multiple case examples is depicted in Figure 1.
Figure 1: Use Case Systematization
|
Strategic Use Case Scope |
Data Source Location |
|
|
Internal |
External |
|
|
Exploitation |
Inside-out Exploitation ● Use of AR filters and lenses to give better shopping recommendations and allow try-on ● Use of pathway data from bluetooth beacons to trace and understand consumer paths within stores |
Outside-in Exploitation ● Use social media chatter to proxy mindset metrics like Awareness, Consideration, or Satisfaction ● Rely on abnormal user chatter and brand and product mentions to identify dangerous events and prevent shitstorms |
|
Exploration |
Inside-out Exploration ● Leverage user behavior data from connected product ecosystems (e.g., Nike+) to develop products and services ● Identify new market and product opportunities from product review data from own e-commerce channels |
Outside-in Exploration ● Uncover customer preferences using social media chatter ● Content-analyze patents to develop technology roadmaps ● Use search-terms to plot consumer’s product perceptions |
source: de Haan et al. (2023)
Outside-in Exploitation of User-Generated Content
While companies usually have a clear idea of how to exploit and explore internal customer data, the remaining two quadrants often remain terra incognita, where companies do not fully leverage the potential at hand. By tracking how often a brand is mentioned favorably (or unfavorably), one can easily enrich or even replace common survey-based brand metrics such as brand awareness, brand liking, or customer satisfaction. These are all well-known and documented to be related to customer actions such as purchase frequency and brand loyalty and thus also tied to other important corporate measures such as profitability and shareholder value. By using user-generated content, companies can continuously monitor daily sentiment scores , and see how brand sentiment is driven by own marketing actions, competitor actions, or market developments.
The number of positive and negative comments about a brand can be used to predict important mindset metrics from awareness over purchase intent to customer satisfaction and recommendation and help marketing managers as well as retail operators to optimize their activities.
When measuring sentiment from user-generated-content, a key task is to understand how to optimally extract it from text-, image-, or video-data. For text data, a wide set of tools already exists that help managers infer sentiment from written data. These tools are commonly separated into two main categories: top-down and bottom-up.
Top-down tools use dictionaries which list words that are associated with sentiments. The tool then simply counts the number of words in a given test associated with a positive or negative sentiment. These tools can also leverage the potential of symbols in text such as emojis, which also express sentiment. By investigating which emojis tend to appear with a brand in user posts, one can often develop a better understanding of brand meaning. By monitoring the usage of emojis over time as highlighted in Figure 2, we can see how positively or negatively consumers talk about brands. Gatorade is well received and benefits from a strong fan base, as indicated by the many positive emojis. Meanwhile, Powerade is less popular and even faces criticism from social media users (as indicated by the thumb down emoji on the first rank).
Figure 2: Analysis of Emojis posted in captions of brand mentions on TikTok
|
|


Bottom-Up tools are more sophisticated AI-based machine learning tools, which rely on pre-labeled training data to measure sentiment. These models try to understand which words frequently occur together in a positive or negative setting. Training these models takes substantial resources and time and machine learning engineering skills. Large Language Models (LLM) such as GPT4 or Google’s BERT model provide marketers with a large base of pre-trained models, which can easily be adapted to their own needs.. IWhen deciding whether to use top-down or bottom-up tools, managers need to weigh costs such as time and financial resources against the tool’s precision. Top-down models are directly applicable, fast, and do not always require coding experience. These tools usually come at the cost of being less precise and producing more general results.
When it comes to measuring sentiment within images and videos, machine learning is again key. State-of-the-art object classifiers can be used to detect products or brand logos and to measure emotions for example by analyzing facial expressions or voices in videos.
Outside-in Exploration of User Generated Content
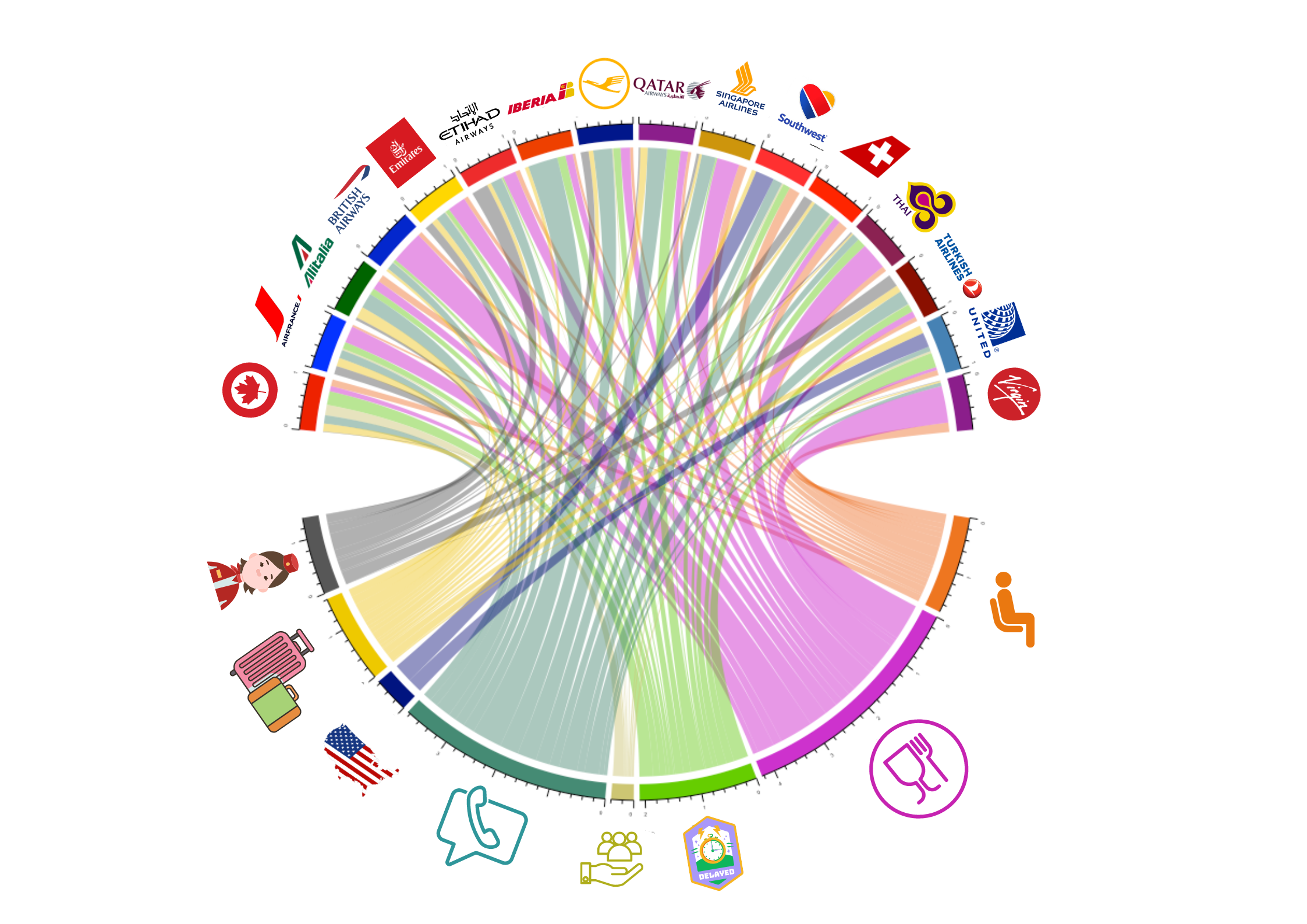
Beside tracking customer mindset, one may similarly be interested in understanding why consumers are (dis)satisfied or the preferences of certain customer segments. To achieve this, Natural Language Processing research has developed topic models, a type of machine learning model that can be applied to different contexts. They screen sets of documents to identify latent topics anchored in each document. Companies can monitor satisfaction drivers, by e.g. analyzing latent topics in product- and service-reviews to understand which topics drive satisfaction and dissatisfaction. Similarly, one can use topic models to understand the strategies of competitors by topic-analyzing large sets of patents, investor reports or the official (corporate) or unofficial (board-members) social media (e.g. LinkedIn) channels of competitors. Topics can be inspected and interpreted in different ways, such as creating word clouds and word frequency plots to visualize key terms. Once one has developed an interpretation of (and names for) the different topics at hand, one can continue with investigating which topics occur more or less frequently for specific brands in an industry as shown in Figure 4, where we see how the eight dominant topics (e.g., seat comfort, booking experience, etc.) in reviews apply to different airlines. By inspecting which airline faces which types of topics, we can then optimize or improve our own brand’s positioning in comparison to our competitors.
Figure 4. Topic shares per airline
UGC-based KPI development and company integration
Given the strong potential of user-generated content, managers are well advised to identify suitable data sources and use cases to enrich their decision making with the help of user-generated content. We suggest the following steps:
-
We recommend first to explore potential questions, where user-generated content can be useful.
-
Managers should then start identifying data sources within and outside of the company.
-
The next step is identifying how to go about data collection and data storage. This step should involve legal inquiries about data ownership and data privacy.
-
Managers should then start focusing on information retrieval by identifying the most suitable tool to extract the information of interest from the raw data. This may on the one hand require managers to consider costs and benefits of the tools at their disposal. . Deciding which tools to use may be driven by the specific use case. In case of an explorative non-permanent approach, easy to use but less efficient tools may be sufficient. If user-generated content is permanently used to track customer perceptions, or to build KPIs, companies should invest more time and resources to develop a customized (i.e. bottom-up) tool.
-
Here, it makes sense to benchmark the obtained measures with other data obtained from surveys, for example, to see how well the user-generated data moves with the established measures and how well user-generated content predicts the company’s bottom-line performance measures such as leads, sales, repeated sales, market share, or profits.
-
As a result, user-generated-content measures can then ultimately be integrated in management dashboards, so that all company stakeholders can rely on the information and use consumer sentiment scores to track brand health or see how their own actions resonate with consumer chatter. This then also requires the responsible managers to brief all involved stakeholders about where data is coming from and how the data is prepared to build these measures.
-
For more information on leveraging user-generated social media data, see Dr. Kübler’s textbook, “Applied Marketing Analytics using R”, co-written with Dr. Gorkhan Yildrim (Imperial College London).







