

par Raoul Kübler
, 27.07.23
Avec Jeroen Rombouts
Nous vivons la période la plus riche en données de l'humanité. Nous créons et stockons quotidiennement plus de données que nos ancêtres ne l'ont fait au cours des 2000 dernières années réunies. Ces données proviennent de diverses sources numériques, où les consommateurs laissent intentionnellement (et non intentionnellement) des informations précieuses pour les spécialistes du marketing sous la forme de contenu généré par les utilisateurs. Raoul Kubler (professeur associé de marketing) et Jeroen Rombouts (professeur de systèmes d'information, de sciences de la décision et de statistiques et titulaire de la chaire ESSEC Accenture Strategic Business Analytics) expliquent ce que ces données peuvent nous apprendre sur le comportement des consommateurs.
Les consommateurs nous fournissent en permanence des informations sur ce qu'ils apprécient chez une marque, sur les produits qu'ils comparent ou qu'ils désirent, sur les aspects d'un service qu'ils n'apprécient pas ou sur les éléments qui les ont particulièrement déçus. Chaque canal en ligne nous fournit des informations spécifiques que nous pouvons utiliser pour obtenir des informations sur le comportement des clients tout au long de leur parcours décisionnel. Le volume de recherche sur Google et le nombre d'abonnés sur les réseaux sociaux peuvent nous donner une idée de la connaissance et de la notoriété de la marque. En ce qui concerne le comportement des consommateurs lors de la recherche d'informations et la réflexion, les requêtes de recherche sur Google ou Bing peuvent également nous permettre de comprendre quels aspects du positionnement de notre marque résonnent dans l'esprit d'un consommateur et quelles autres marques et produits du marché sont perçus comme égaux, supérieurs ou inférieurs à notre produit.
Plus bas dans l’entonnoir, le contenu généré par les utilisateurs à partir des réseaux sociaux peut également nous aider à suivre les ressentis, les préférences et les attitudes des clients et à comprendre les indicateurs tels que l'intention d'achat, la perception de la marque ou la satisfaction du client. Instagram est connu pour être utilisé pour faire l'éloge des marques et mettre en évidence les produits qui sont à la mode, et peut être une excellente source pour suivre l'évolution de la notoriété d'une marque. Twitter est tristement célèbre pour être le premier endroit où se plaindre si les attentes des consommateurs ne sont pas satisfaites. Cela signifie que ces deux canaux peuvent être utiles pour suivre la satisfaction des clients et la perception de la marque. De même, des plateformes telles que Facebook (pour un groupe cible plus âgé), TikTok (pour un groupe cible plus jeune), YouTube, Reddit et Snapchat fournissent aux responsables de nombreuses informations sur les clients. Les spécialistes du marketing peuvent comprendre la perception qu'ont les consommateurs de leur marque (et la manière dont ils sont influencés par leurs activités marketing) en examinant le contenu qu'ils publient et en déterminant à quel point il est apprécié par rapport à d'autres marques. Ce même vivier de données nous permet de suivre l'état d'esprit des clients et de l'expliquer par les activités marketing, mais aussi d'identifier et de mesurer les préférences et les opinions des consommateurs afin d'identifier de nouveaux segments, des cas d'utilisation de produits et des opportunités de croissance. Pour exploiter ce contenu généré par les utilisateurs, les managers doivent comprendre clairement quel type d'information, pour quel type de cas d'utilisation ils veulent extraire, afin de décider ensuite quelles sources de données et quels outils sont nécessaires pour générer de l'information. Nous donnons ci-après un aperçu des cas d'utilisation potentiels, des sources de données correspondantes et des outils de pointe permettant d'analyser les différents types de données.
Types de cas d’utilisation et applications en entreprise
En ce qui concerne les cas d'utilisation, des recherches récentes proposent un cadre qui combine la source des données et la portée du cas d'utilisation de l'entreprise. Dans ce cadre, les données proviennent de deux sources principales : les données générées à l'intérieur de l'entreprise et les données qui doivent être collectées à l'extérieur. Les entreprises peuvent utiliser ces données soit pour comprendre les consommateurs et les marchés, soit pour les exploiter afin de prendre des décisions plus éclairées. Le tableau 1 illustre la matrice à deux dimensions qui en résulte, avec de multiples exemples de cas.
Tableau 1: Structuration des cas d’utilisation
|
Application stratégique des cas d’utilisation |
Provenance de la source des données |
|
|
Interne |
Externe |
|
|
Exploitation |
Exploitation de l’intérieur à l’extérieur ● Créer et permettre l’utilisation de filtres en réalité augmentée pour donner de meilleures recommandations d'achat et permettre de faire des essayages. ● Exploiter les données générées par des balises Bluetooth pour suivre et comprendre le parcours des consommateurs en magasin. |
Exploitation de l’extérieur à l’intérieur ● Utiliser les données des chats des réseaux sociaux pour évaluer la notoriété, la considération et la satisfaction client. ● S'appuyer sur les conversations inhabituelles des utilisateurs et sur les mentions de marques et de produits pour identifier les événements indésirables et prévenir les catastrophes. |
|
Compréhension |
Compréhension de l’intérieur à l’extérieur ● Utiliser les données sur le comportement des utilisateurs provenant d'écosystèmes de produits connectés (par exemple, Nike+) pour développer des produits et des services. ● Identifier de nouvelles opportunités de marché et de produits à partir des données d'évaluation des produits provenant de ses canaux de ventes en ligne. |
Compréhension de l’extérieur à l’intérieur ● Découvrir les préférences des clients à partir des conversations sur les réseaux sociaux. ● Analyser le contenu des brevets pour construire une feuille de route technologique. ● Utiliser les mots-clés pour tracer les perceptions des consommateurs sur les produits. |
Source : de Haan et al. (2023)
Exploitation de contenu généré par les utilisateurs de l’extérieur à l’intérieur
Alors que les entreprises ont généralement une idée claire de la manière d'exploiter et de comprendre les données clients internes, les deux autres cases restent souvent terra incognita, où les entreprises n'exploitent pas pleinement le potentiel à leur disposition. En suivant la fréquence à laquelle une marque est mentionnée favorablement (ou défavorablement), il est possible d'enrichir, voire de remplacer, les indicateurs de marque courants basés sur des enquêtes, tels que la notoriété de la marque, l'appréciation de la marque ou la satisfaction de la clientèle. Ces indicateurs sont tous bien connus et documentés pour être liés aux comportements des consommateurs, tels que la fréquence d'achat et la fidélité à la marque, et donc également liés à d'autres indicateurs importants pour l'entreprise, tels que la rentabilité et la valeur actionnariale. En utilisant le contenu généré par les utilisateurs, les entreprises peuvent surveiller en permanence les statistiques quotidiennes sur le ressenti de la marque, et voir comment ce ressenti est influencé par leurs propres activités de marketing, les activités de leurs concurrents ou l'évolution du marché.
Le nombre de commentaires positifs et négatifs sur une marque peut être utilisé pour prédire des indicateurs importants de perception, de notoriété, d'intention d'achat, de satisfaction client et de recommandation, et aider les responsables du marketing ainsi que les exploitants de vente au détail à optimiser leurs activités.
Lorsqu'il s'agit de mesurer le ressenti à partir d'un contenu généré par l'utilisateur, une tâche essentielle consiste à comprendre comment l'extraire de manière optimale à partir de données textuelles, d'images ou de vidéos. Pour les données textuelles, il existe déjà un large éventail d'outils qui aident les gestionnaires à déduire le ressenti des données écrites. Ces outils sont généralement classés en deux catégories principales : les outils top-down (descendants) et les outils bottom-up (ascendants).
Les outils top-down utilisent des dictionnaires qui répertorient les mots associés au ressenti. L'outil compte alors simplement le nombre de mots d'un test donné associés à un sentiment positif ou négatif. Ces outils peuvent également exploiter le potentiel des symboles présents dans le texte, tels que les emojis, qui expriment également un sentiment. En étudiant les emojis qui ont tendance à apparaître avec une marque dans les messages des utilisateurs, il est souvent possible de mieux comprendre la perception de la marque. En suivant l'utilisation des emojis au fil du temps, comme le montre le tableau 2, nous pouvons voir dans quelle mesure les consommateurs parlent des marques de manière positive ou négative. Gatorade est bien accueilli et bénéficie d'une forte base de fans, comme l'indiquent les nombreux emojis positifs. En revanche, Powerade est moins populaire et fait même l'objet de critiques de la part des utilisateurs des réseaux sociaux (comme l'indique l'emoji "pouce vers le bas" au premier rang).
Tableau 2 : Analyse des Emojis postés dans les légendes des mentions de marques sur TikTok
|
|


Les outils bottom-up sont des outils de machine learning plus sophistiqués, basés sur l'IA, qui s'appuient sur des jeux de données d'apprentissage pré-étiquetés pour mesurer le ressenti. Ces modèles tentent de comprendre quels sont les mots qui reviennent fréquemment ensemble dans un contexte positif ou négatif. L'apprentissage de ces modèles nécessite des ressources et du temps considérables, ainsi que des compétences en ingénierie de machine learning. Les grands modèles de langage (LLM) tels que GPT4 ou le modèle BERT de Google fournissent aux spécialistes du marketing une large base de modèles pré-entraînés, qui peuvent facilement être adaptés à leurs propres besoins.... Lorsqu'ils décident d'utiliser des outils top-down ou bottom-up, les managers doivent évaluer les coûts, tels que le temps et les ressources financières, par rapport à la précision de l'outil. Les modèles top-down sont directement applicables, rapides et ne requièrent pas toujours d'expérience en matière de codage. Ces outils ont généralement pour contrepartie d'être moins précis et de produire des résultats plus généraux.
Lorsqu'il s'agit de mesurer le ressenti dans des images et des vidéos, le machine learning est une fois de plus la clé. Des classificateurs d'objets de pointe peuvent être utilisés pour détecter des produits ou des logos de marque et pour mesurer les émotions, par exemple en analysant les expressions faciales ou les voix dans les vidéos.
Compréhension de contenu généré par les utilisateurs de l’extérieur à l’intérieur
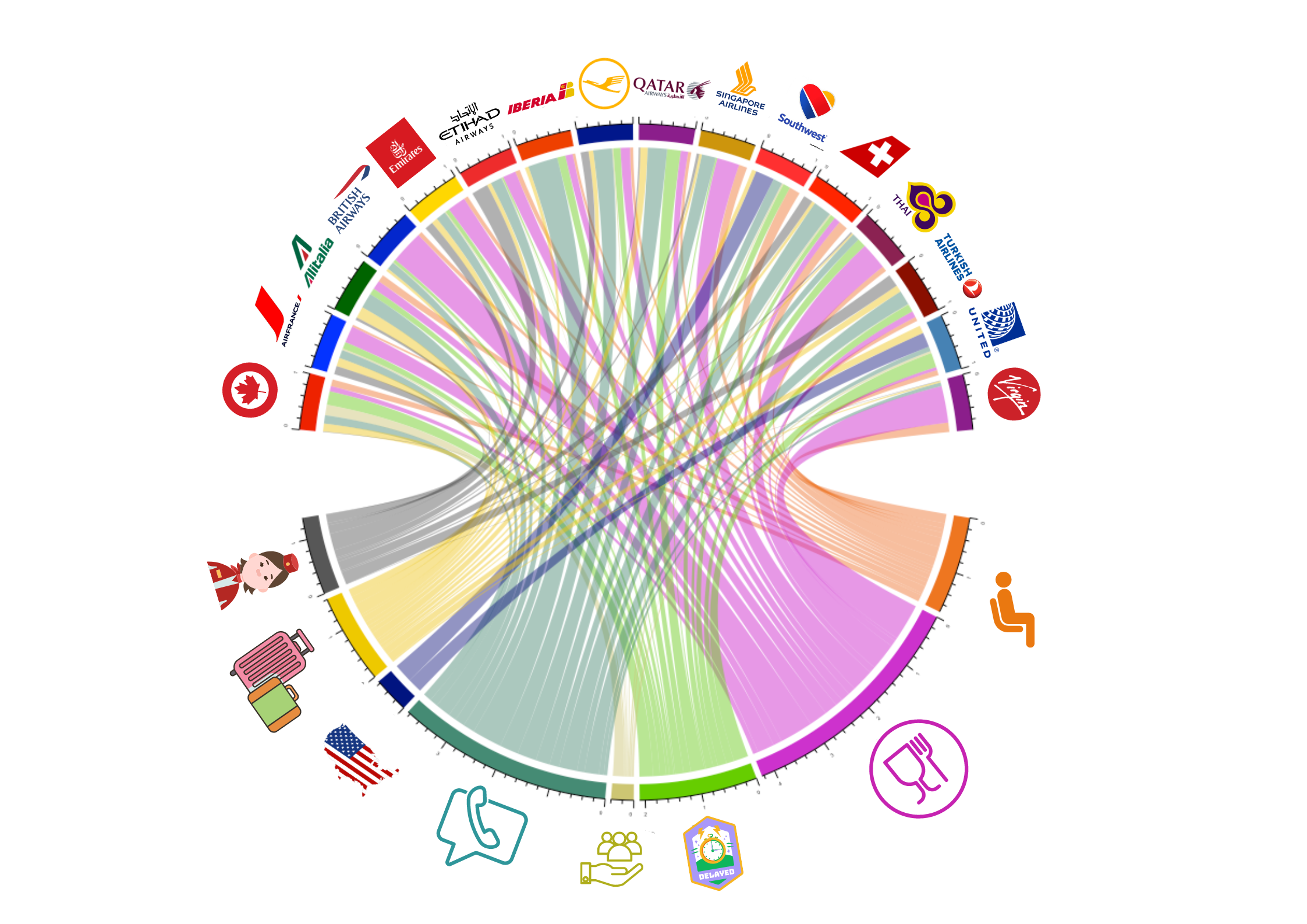
Outre le suivi de l'état d'esprit des clients, il peut également être intéressant de comprendre pourquoi les consommateurs sont (dé)satisfaits ou quelles sont les préférences de certains segments de clientèle. Pour ce faire, la recherche sur le traitement du langage naturel a développé des modèles thématiques, un type de modèle d'apprentissage automatique qui peut être appliqué à différents contextes. Ils passent au crible des ensembles de documents afin d'identifier les sujets latents ancrés dans chaque document. Les entreprises peuvent surveiller les facteurs de satisfaction, par exemple en analysant les sujets latents dans les évaluations de produits et de services afin de comprendre quels sont les sujets qui déterminent la satisfaction et l'insatisfaction. De même, il est possible d'utiliser des modèles thématiques pour comprendre les stratégies des concurrents en analysant les thèmes de vastes ensembles de brevets, de rapports d'investisseurs ou de canaux de médias sociaux officiels (entreprise) ou non officiels (membres du conseil d'administration) des concurrents (par exemple, LinkedIn). Les sujets peuvent être inspectés et interprétés de différentes manières, par exemple en créant des nuages de mots et des diagrammes de fréquence de mots pour visualiser les termes clés. Une fois que l'on a développé une interprétation (et des noms) pour les différents sujets en question, on peut continuer à étudier quels sujets apparaissent plus ou moins fréquemment pour des marques spécifiques dans un secteur, comme le montre la figure 3, où l'on voit comment les huit sujets dominants (par exemple, le confort du siège, l'expérience de la réservation, etc. En examinant quelle compagnie aérienne est confrontée à quels types de sujets, nous pouvons optimiser ou améliorer le positionnement de notre propre marque par rapport à nos concurrents.
Figure 3. Les sujets associés à chaque compagnie aérienne
Développement d'indicateurs clés de performance basés sur le contenu généré par les utilisateurs et intégration de l'entreprise
Étant donné le fort potentiel du contenu généré par les utilisateurs, les managers ont tout intérêt à identifier les sources de données et les cas d'utilisation appropriés pour enrichir leur prise de décision à l'aide du contenu généré par les utilisateurs. Nous suggérons les étapes suivantes :
-
Nous recommandons d'abord de réfléchir aux potentielles questions pour lesquelles le contenu généré par les utilisateurs peut s'avérer utile.
-
Les managers doivent alors commencer à identifier les sources de données à l'intérieur et à l'extérieur de l'entreprise.
-
L'étape suivante consiste à déterminer comment procéder à la collecte et au stockage des données. Cette étape devrait impliquer des recherches juridiques sur la propriété des données et la protection de la vie privée.
-
Les managers doivent alors se concentrer sur la récupération d'informations en identifiant l'outil le plus approprié pour extraire les informations intéressantes des données brutes. Cela peut, d'une part, obliger les managers à considérer les coûts et les bénéfices des outils à leur disposition. Le choix des outils à utiliser peut être dicté par le cas d'utilisation spécifique. Dans le cas d'une approche exploratoire non permanente, des outils faciles à utiliser mais moins efficaces peuvent suffire. Si le contenu généré par les utilisateurs est utilisé de manière permanente pour suivre les perceptions des clients ou pour établir des indicateurs de performance clés, les entreprises devraient investir plus de temps et de ressources pour développer un outil personnalisé (c’est-à-dire bottom-up).
-
Dans ce cas, il est judicieux de comparer les résultats obtenus avec d'autres données obtenues à partir d'enquêtes, par exemple, afin de déterminer dans quelle mesure les données générées par les utilisateurs correspondent aux résultats établis et dans quelle mesure le contenu généré par les utilisateurs permet de prédire les résultats de l'entreprise, tels que les prospects, les ventes, les ventes répétées, la part de marché ou les bénéfices.
-
En conséquence, les résultats des évaluations du contenu généré par les utilisateurs peuvent être intégrés dans les tableaux de bord, de sorte que toutes les parties prenantes de l'entreprise puissent s'appuyer sur ces informations et utiliser les scores du ressenti des consommateurs pour suivre la performance de la marque ou voir comment leurs propres actions s'inscrivent dans le cadre des conversations des consommateurs. Pour ce faire, les managers responsables doivent également informer toutes les parties prenantes concernées de l'origine des données et de la manière dont elles sont préparées pour établir ces résultats.
-
Pour plus d'informations sur l'exploitation des données des réseaux sociaux générées par les utilisateurs, voir le manuel du Professeur Kübler, "Applied Marketing Analytics using R", coécrit avec le professeur Gorkhan Yildrim (Imperial College London).







